
The Issue…
After performing an update to a server I maintain (moving from Debian 10 (Buster) to Debian 11 (Bullseye), the installed version of Exim moved from 4.92.x to 4.94.2. Along with noted changes needed to ensure that the config didn’t fall foul of the restrictions around taints, I started to notice some odd behaviour, but only when delivering mail, and large mail at that (eg with attachments – a hundred kB or so was enough), to Google MX hosts.
Google mail delivery has never previously been an issue – the usual suspects have been Yahoo and Hotmail. However, this time I was seeing mail queue entries that hung around for hours and hours for no apparent reason: the mail address was absolutely valid, I could deliver other mail to the target, and indeed mail with attachments through other outbound SMTP servers. Eventually, delivery would work, but after a delay (sometime substantial).
The only clue I had in mainlog were entries like:
/var/log/exim4/mainlog:2022-04-27 07:47:30 1njbGQ-005LxL-M5 H=gmail-smtp-in.l.google.com [2a00:1450:4010:c0e::1a]: SMTP timeout after sending data block (199774 bytes written): Connection timed out /var/log/exim4/mainlog:2022-04-27 07:50:10 1njbGU-005Lz8-RV H=gmail-smtp-in.l.google.com [74.125.131.26]: SMTP timeout after end of data (246239 bytes written): Connection timed out
It didn’t appear ipv4/v6 made a difference (see above), and running exim in debug mode wasn’t particularly informative:
1315427 tls_write(0x55941d1d57b0, 8191) 1315427 gnutls_record_send(session=0x55941d2a3cc0, buffer=0x55941d1d57b0, left=8191) 1315427 outbytes=8191 1315427 flushing headers buffer 1315427 writing data block fd=6 size=8191 timeout=300 1315427 tls_write(0x55941d1d57b0, 8191) 1315427 gnutls_record_send(session=0x55941d2a3cc0, buffer=0x55941d1d57b0, left=8191) 1315427 GnuTLS<3>: ASSERT: ../../lib/buffers.c[_gnutls_io_write_flush]:727 1315427 GnuTLS<3>: ASSERT: ../../lib/record.c[_gnutls_send_tlen_int]:582 1315427 GnuTLS<2>: WRITE: -1 returned from 0x6, errno: 104 1315427 GnuTLS<3>: ASSERT: ../../lib/buffers.c[_gnutls_io_write_flush]:722 1315427 GnuTLS<3>: ASSERT: ../../lib/record.c[_gnutls_send_tlen_int]:589 1315427 outbytes=-110 1315427 tls_write: gnutls_record_send err 1315427 LOG: MAIN 1315427 H=aspmx.l.google.com [2a00:1450:400c:c07::1a] TLS error on connection (send): The TLS connection was non-properly terminated. 1315427 ok=0 send_quit=0 send_rset=1 continue_more=0 yield=1 first_address is NULL 1315427 tls_close(): shutting down TLS 1315427 GnuTLS<2>: WRITE: -1 returned from 0x6, errno: 32 1315427 GnuTLS<3>: ASSERT: ../../lib/buffers.c[errno_to_gerr]:230 1315427 GnuTLS<3>: ASSERT: ../../lib/buffers.c[_gnutls_io_write_flush]:722 1315427 GnuTLS<3>: ASSERT: ../../lib/record.c[gnutls_bye]:294 1315427 SMTP(close)>> 1315427 LOG: MAIN 1315427 H=aspmx.l.google.com [2a00:1450:400c:c07::1a]: SMTP timeout after sending data block (289658 bytes written): Connection timed out 1315427 set_process_info: 1315427 delivering 1njm9Z-005WCX-HC: just tried aspmx.l.google.com [2a00:1450:400c:c07::1a] for myusername@mydomain.com: result DEFER 1315427 added retry item for T:aspmx.l.google.com:2a00:1450:400c:c07::1a: errno=110 more_errno=0,M flags=2
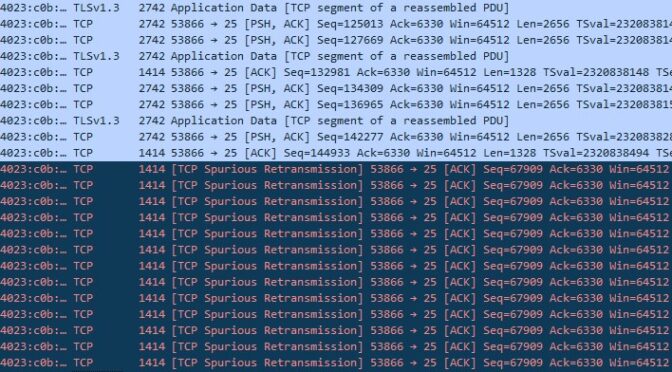
A packet trace gave a slightly more interesting, but not particularly informative set of results, which indicate that there are multiple retries of a TCP segment for which the ACK has already been received from the Google server.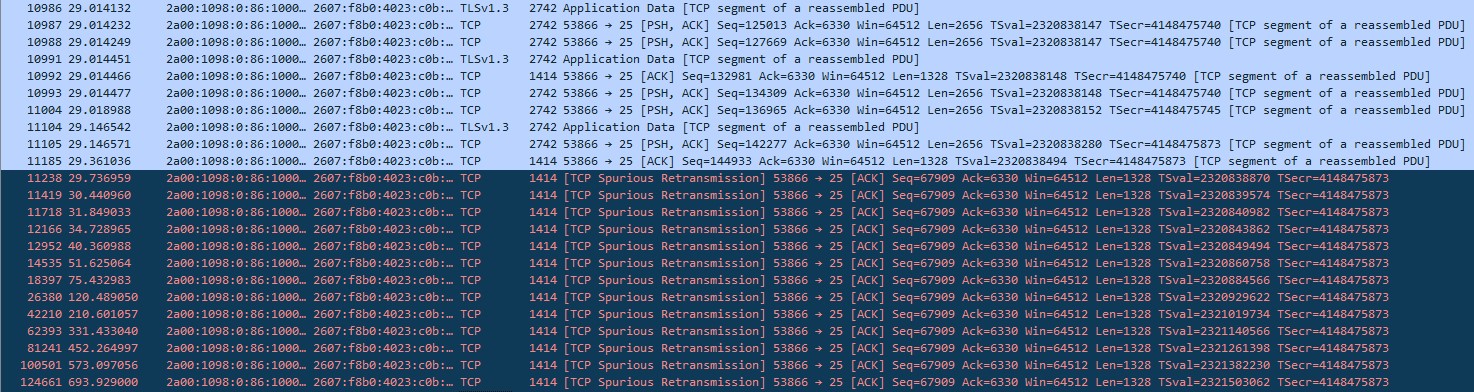
If I set:
sysctl net.ipv4.tcp_window_scaling=0
(i.e. turning off TCP Window Resizing in the kernel) then things worked fine, but this has the non-trivial side-effect of majorly affecting all network performance. Setting TCP Window Scaling back to “on” landed me with the issue again. At least it was reproducible…
The Workaround…
A post by Adam Barratt suggested that this was to do with TCP Fast Open (and specifically with Google’s implementation), though the referenced blog post seemed to indicate a different set of symptoms.
Still, I gave this a whirl by adding:
hosts_try_fastopen = !*.l.google.com
into /etc/exim4/conf.d/transports/30_exim4-config_remote_smtp . Usefully, at the time of the first test, I had a load of mailq entries for mail going to Google hosts which had previously failed delivery as above. On restart of the exim4 processes, everything cleared itself on first queue run – and I’ve not seen any issues in the logs since (have been running this for 3 weeks+ now).
Quite why disabling TCP Fast Open for these hosts works, I’m not sure – it looks like it might be a combination of factors in the Debian release according to Adam’s post as above, but it’s not really an Exim bug at all as it does everything correctly: chalk one up to Google doing something very odd. EDIT: This is a kernel bug as reported at: https://lore.kernel.org/lkml/E1nZMdl-0006nG-0J@plastiekpoot/ and is fixed in the 5.18 kernel which (as of 10-Aug-2022 is available in Debian Testing), but in the interim, at least until either users are brave enough to switch to a Testing kernel, or the kernel gets released into Stable, the above workround seems appropriate.
Either way, not an obvious solution to a very weird problem where everything “just worked” prior to upgrade, but hopefully this might help some other exim admins who are scratching their heads as well…